
Article scientifique original disponible sur arXiv (en anglais)
Depuis la sortie de ChatGPT [5] en novembre 2022, les modèles de langage de grande taille (LLMs) [1] ont connu un succès considérable, y compris dans la communauté open-source, avec de nombreux modèles à poids ouverts disponibles. Cependant, les exigences pour déployer un tel service sont souvent inconnues et difficiles à évaluer à l'avance. Pour faciliter ce processus, nous avons mené de nombreux tests au Centre Inria de l'Université de Bordeaux. Dans cet article, nous proposons une comparaison des performances de plusieurs modèles de différentes tailles (principalement Mistral [2][3] et LLaMa [4]) en fonction des GPU disponibles, en utilisant vLLM [8], une bibliothèque Python conçue pour optimiser l'inférence de ces modèles. Nos résultats fournissent des informations précieuses pour les groupes privés et publics souhaitant déployer des LLMs, leur permettant d'évaluer les performances de différents modèles en fonction de leur matériel disponible. Cette étude contribue donc à faciliter l'adoption et l'utilisation de ces grands modèles de langage dans divers domaines d'application.
Suite à la sortie de ChatGPT par OpenAI en novembre 2022 [5], les modèles de langage de grande taille (LLMs) [1] ont suscité un grand intérêt dans le secteur privé, avec de nombreuses entreprises cherchant à offrir des services basés sur ces modèles. Cependant, l'entraînement et l'inférence de tels modèles restent inaccessibles au grand public, nécessitant une puissance de calcul considérable et des données de haute qualité. Par exemple, Meta AI a acquis 350 000 GPU NVIDIA H100 en janvier 2024, pour un coût estimé à 9 milliards de dollars, spécifiquement pour l'entraînement des LLMs. Leur entraînement de LLaMa-3 a été réalisé sur $14*10^{12}$ jetons.
Certaines entreprises pionnières ont rapidement réalisé qu'elles pouvaient bénéficier d'un monopole sur cette avancée technologique, leur conférant un pouvoir décisionnel sans précédent. Pour s'assurer qu'elles conservent ce monopole, ces entreprises font désormais du lobbying auprès des gouvernements pour la réglementation de ces modèles, en invoquant les risques et les dangers potentiels de leur utilisation malveillante. Elles proposent des mesures allant de l'interdiction de l'entraînement de modèles au-delà d'une certaine puissance de calcul au contrôle gouvernemental des GPU, avec la possibilité de désactivation à distance [12].
Cependant, il est essentiel que ces outils ne soient pas uniquement entre les mains de quelques acteurs puissants, capables d'influencer les biais de leurs modèles qu'ils distribuent à grande échelle, leur permettant ainsi une influence de masse. La transparence de ces modèles, avec l'ouverture des données d'entraînement et des poids associés, est la solution la plus appropriée pour permettre à toute entité externe de vérifier la fiabilité et la sécurité des modèles proposés. Bien que cette approche ne soit pas appréciée par la majorité de ces entreprises, certaines d'entre elles, comme Meta et Mistral, investissent massivement dans des modèles à poids ouverts, distribuant librement des variantes de leurs modèles LlaMa [4] et Mistral [2][3].
Grâce à ces efforts, de nombreux groupes, tant publics que privés, sont désormais en mesure de déployer des modèles puissants, assurant ainsi la souveraineté de leurs données et évitant la concentration de cette richesse et de ce potentiel en un seul point. Cependant, même si ces modèles sont disponibles pour tous, il n'est pas facile de les déployer ou d'estimer les ressources nécessaires pour le faire. Bien qu'il soit simple de servir un modèle à un utilisateur, il est beaucoup plus complexe de le déployer pour des dizaines, des centaines, voire des milliers d'utilisateurs simultanés. Dans ce contexte, nous avons mené plusieurs tests au Centre Inria de l'Université de Bordeaux concernant le déploiement de tels modèles.
L'objectif principal de notre étude est de répondre aux préoccupations de sécurité et de confidentialité soulevées par l'utilisation croissante de solutions LLM propriétaires - telles que ChatGPT - par les étudiants et les chercheurs du Centre Inria de l'Université de Bordeaux. En effet, une grande partie de nos étudiants utilisent ces outils pour les aider dans leur travail quotidien, qu'il s'agisse d'écriture, de programmation, de relecture d'articles ou de brainstorming.
Cependant, l'utilisation de ces solutions propriétaires soulève de sérieuses questions de sécurité et de confidentialité. Elles ne garantissent pas la confidentialité des données, et les intérêts privés derrière elles peuvent potentiellement les utiliser à des fins commerciales, de formation ou même d'espionnage industriel. Ce dernier point est particulièrement préoccupant pour un centre de recherche comme Inria, qui doit assurer la confidentialité du travail de recherche de ses employés et qui est en concurrence directe avec les entreprises offrant ces solutions propriétaires.
Il est donc crucial pour Inria de proposer des solutions alternatives et de préserver sa souveraineté numérique. De plus, étant donné l'importance croissante de cette technologie, de plus en plus de chercheurs et d'étudiants souhaitent mener des expériences basées sur les LLMs. Par exemple, la mise en place de systèmes RAG (Retrieval Augmented Generation) [6][7] est une application courante dans le monde des affaires, qui consiste à utiliser un LLM pour "discuter" avec ses données. Il serait donc intéressant de leur offrir un service adapté.
Pour déployer un LLM sur un GPU, certaines connaissances et compétences sont requises en développement Linux et Python, ainsi qu'une grande curiosité pour les modèles existants et la quantification. Bien que la compréhension du fonctionnement interne des Transformers ne soit pas nécessaire, elle peut être un atout.
Les compétences requises incluent la capacité à mettre à jour les pilotes CUDA (version 12 minimum), installer une version de Python (minimum 3.9), installer les dépendances Python, effectuer des requêtes HTTP, et choisir le bon modèle pour votre cas d'utilisation, quantifié ou non en fonction de vos ressources.
Nous avons mené nos tests sur le serveur de calcul Plafrim, équipé de deux types de GPU :
Nous avons utilisé vLLM [8], une bibliothèque Python conçue pour optimiser l'inférence de ces modèles. Cette bibliothèque nécessite au moins l'installation préalable de Python 3.9 et CUDA 12.
L'avantage de vLLM par rapport à d'autres solutions est sa capacité à gérer plusieurs requêtes simultanément, sans file d'attente et sans augmentation linéaire du temps de calcul en fonction du nombre de requêtes, mais plutôt logarithmique.
Cependant, en fonction du matériel disponible, d'autres solutions peuvent être envisagées. Notamment, tensorRT-LLM offre d'excellentes performances avec les GPU NVIDIA, et lllama.cpp fournit des performances remarquables sur les Mac équipés de puces M1, M2 ou M3.
Certains modèles peuvent être très volumineux, ce qui rend particulièrement difficile leur chargement dans le matériel disponible - limité par sa VRAM.
Pour résoudre ce problème, l'une des meilleures solutions est de quantifier nos modèles. Au lieu d'écrire les valeurs de nos poids sur 16 ou 32 bits, nous pouvons accepter une légère perte de précision et les écrire sur 4 ou 8 bits.
Cette perte a été évaluée plusieurs fois, et bien qu'elle varie en fonction des modèles et des méthodes de quantification utilisées, nous pouvons affirmer qu'elle est négligeable jusqu'à 6 bits et acceptable jusqu'à 4 bits. Cependant, pour un nombre de paramètres supérieur à 70 milliards, les modèles sont suffisamment robustes pour permettre une quantification inférieure à 4 bits tout en maintenant une bonne cohérence.
Parmi les différentes méthodes de quantification [10], nous pouvons mentionner AWQ [9], GPTQ [11] et GGUF (llama.cpp).
Dans cette étude, nous cherchons à déterminer la charge maximale de requêtes simultanées qu'un serveur équipé de GPU V100 16 GB ou A100 40 GB peut supporter, en fonction du LLM utilisé. Pour cela, nous avons mené des tests en augmentant progressivement le nombre de requêtes simultanées et la taille des invites, jusqu'à atteindre la charge maximale. Pour chaque requête, nous avons mesuré le temps nécessaire pour générer 100 jetons. Et, pour chaque modèle et GPU, nous avons mesuré la charge de mémoire, la vitesse d'exécution et le nombre de jetons par seconde en fonction du nombre de requêtes simultanées et de la taille maximale du contexte.
Nous avons choisi de nous concentrer principalement sur les modèles proposés par Mistral AI [2][3], en raison de leur diversité, de leur popularité et de leurs compétences. Nous apprécions également leurs performances sur les langues européennes, en particulier le français. De plus, leur architecture Mixture of Experts [3] permet des économies de calcul lors de l'inférence, en ne sélectionnant qu'une partie des poids du modèle à chaque étape, ce qui réduit également la consommation d'énergie.
De plus, nous avons inclus le modèle LLaMa-3-70B [4] de Meta, qui atteint des performances comparables à GPT-4 avec ses 70 milliards de paramètres. Cette taille de modèle semble être un bon compromis entre taille et performance, justifiant son inclusion dans notre étude.
Ainsi, nous avons testé les modèles suivants :
| Requests | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 1.8 | 1.8 | 1.9 | 1.9 | 1.9 | 2.1 | 2.3 |
| 2 | 2.1 | 2.1 | 2.0 | 2.2 | 2.3 | 2.6 | 2.8 |
| 4 | 2.2 | 2.3 | 2.1 | 2.6 | 2.5 | 2.8 | 3.7 |
| 8 | 2.4 | 2.4 | 2.5 | 2.7 | 3.0 | 3.5 | 5.9 |
| 16 | 2.9 | 2.9 | 3.0 | 3.8 | 4.2 | 5.2 | 9.2 |
| 32 | 4.2 | 4.2 | 4.5 | 5.4 | 6.9 | 8.8 | 19.0 |
| 64 | 6.7 | 7.1 | 7.7 | 9.8 | 11.9 | 17.1 | 36.0 |
| 128 | 10.6 | 10.4 | 11.5 | 16.2 | 24.4 | 33.3 | 72.1 |
| Requêtes | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 2.3 | 2.3 | 2.4 | 2.5 | 2.6 | 2.6 | 3.0 |
| 2 | 2.3 | 2.4 | 2.5 | 2.7 | 2.7 | 2.8 | 3.5 |
| 4 | 2.4 | 2.5 | 2.6 | 2.8 | 3.0 | 3.4 | 4.8 |
| 8 | 2.6 | 2.7 | 2.8 | 3.2 | 3.7 | 4.5 | 7.4 |
| 16 | 3.0 | 3.2 | 3.4 | 4.2 | 5.0 | 6.4 | 12.3 |
| 32 | 4.5 | 4.8 | 5.4 | 6.7 | 8.4 | 11.4 | 23.1 |
| 64 | 7.9 | 8.5 | 9.3 | 12.3 | 15.8 | 21.6 | 47.7 |
| 128 | 14.3 | 15.4 | 17.6 | 24.2 | 29.9 | 46.4 | 96.2 |
| Requêtes | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 3.1 | 3.2 | 3.2 | 3.3 | 3.4 | 3.7 | 4.3 |
| 2 | 3.3 | 3.4 | 3.4 | 3.6 | 4.0 | 4.4 | 5.8 |
| 4 | 3.7 | 3.8 | 3.9 | 4.4 | 4.8 | 5.6 | 8.8 |
| 8 | 4.8 | 5.1 | 5.3 | 6.0 | 6.8 | 8.8 | 15 |
| 16 | 7.1 | 7.5 | 7.9 | 9.8 | 11.7 | 14.3 | 27.5 |
| 32 | 10.4 | 10.9 | 11.9 | 15.3 | 19.0 | 24.6 | 53.8 |
| 64 | 15.5 | 17.0 | 18.7 | 25.9 | 32.1 | 43.9 | 108.2 |
| 128 | 21.7 | - | - | - | - | - | - |
| Requêtes | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 2.3 | 2.3 | 2.4 | 2.4 | 2.5 | 2.6 | 2.8 |
| 2 | 2.3 | 2.3 | 2.4 | 2.5 | 2.6 | 2.7 | 3.3 |
| 4 | 2.4 | 2.4 | 2.5 | 2.7 | 2.8 | 3.1 | 4.2 |
| 8 | 2.5 | 2.6 | 2.8 | 3.1 | 3.4 | 4.1 | 6.3 |
| 16 | 2.8 | 2.9 | 3.2 | 3.8 | 4.4 | 5.6 | 10.2 |
| 32 | 3.3 | 3.7 | 4.0 | 5.2 | 6.4 | 8.8 | 18.1 |
| 64 | 4.3 | 4.6 | 5.7 | 8.0 | 10.5 | 15.5 | 36.8 |
| 128 | 6.8 | 7.8 | 9.4 | 14.5 | 19.6 | 32.9 | 71.1 |
| Requêtes | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 3.1 | 3.2 | 3.6 | 3.4 | 3.5 | 3.5 | 4.1 |
| 2 | 3.3 | 3.3 | 3.5 | 3.5 | 3.8 | 3.8 | 4.7 |
| 4 | 3.5 | 3.6 | 3.5 | 4.3 | 4.1 | 4.6 | 6.2 |
| 8 | 3.8 | 3.8 | 4.0 | 4.3 | 4.9 | 5.7 | 9.3 |
| 16 | 4.3 | 4.6 | 4.9 | 6.0 | 6.7 | 8.5 | 15.5 |
| 32 | 6.0 | 6.4 | 7.6 | 8.7 | 10.9 | 14.2 | - |
| 64 | 10.0 | 10.5 | 11.6 | 15.5 | - | - | - |
| 128 | 18.5 | 19.6 | 21.5 | - | - | - | - |
| Requêtes | 31 | 63 | 119 | 296 | 480 | 822 | 2193 |
|---|---|---|---|---|---|---|---|
| 1 | 6.0 | 6.0 | 6.3 | 6.8 | 7.0 | 7.6 | 10.9 |
| 2 | 7.2 | 7.1 | 7.4 | 8.4 | 8.7 | 10.3 | 16.7 |
| 4 | 8.0 | 8.1 | 8.7 | 10.3 | 11.9 | 14.2 | 21.3 |
| 8 | 9.0 | 9.4 | 10.0 | 13.0 | 16.7 | 19.4 | 36.2 |
| 16 | 11.0 | 12.2 | 13.2 | 21.1 | 26.5 | 31.9 | 66.4 |
| 32 | 16.0 | 17.6 | 22.6 | 33.6 | 37.7 | 56.7 | - |
| 64 | 28.0 | 31.8 | 35.9 | 56.0 | 71.7 | - | - |
| 128 | 52.0 | 55.3 | 67.0 | 111.7 | - | - | - |
| Requêtes | 21 | 51 | 97 | 240 | 398 | 703 | 1848 |
|---|---|---|---|---|---|---|---|
| 1 | 3.6 | 3.7 | 3.7 | 3.9 | 4.0 | 4.2 | 4.8 |
| 2 | 3.7 | 3.7 | 3.9 | 4.1 | 4.2 | 4.5 | 5.8 |
| 4 | 3.8 | 4.0 | 4.1 | 4.4 | 4.7 | 5.4 | 7.9 |
| 8 | 4.3 | 4.5 | 4.8 | 5.1 | 5.9 | 7.4 | 12.5 |
| 16 | 4.9 | 5.2 | 5.7 | 6.9 | 8.3 | 10.8 | 21.4 |
| 32 | 7.6 | 8.2 | 8.7 | 11.1 | 13.7 | 19.6 | 40.9 |
| 64 | 12.9 | 13.9 | 15.2 | 20.3 | 25.8 | 37.5 | - |
| 128 | 23.2 | - | - | - | - | - | - |
La première chose que nous pouvons remarquer est que plus la taille du contexte est grande, plus le modèle est lent à générer 100 jetons. Cela est attendu et est lié à sa complexité, qui croît de manière quadratique avec la taille du contexte.
De plus, comme nous pouvons le voir avec les modèles Mixtral [3] et Llama [4], le fait qu'un modèle puisse être chargé ne signifie pas qu'il puisse être utilisé pour n'importe quelle taille de contexte. La taille du contexte a un coût quadratique en RAM (ou VRAM), qui s'ajoute à la taille du modèle, augmentant potentiellement de manière significative les exigences en mémoire.
D'autre part, nous pouvons également observer que nous n'avons pas une perte d'efficacité linéaire avec le nombre de requêtes simultanées : le temps nécessaire pour répondre à une requête ne double pas lorsque le nombre de requêtes simultanées double. Cependant, cela semble moins vrai lorsque la taille de la requête dépasse un certain seuil.
Enfin, nous pouvons remarquer que bien que le coût de ces GPU soit loin d'être trivial (V100 16GB ≈ $5000, A100 40GB ≈ $8500), il n'est pas nécessaire de posséder une quantité exorbitante pour exécuter avec succès une alternative locale à ChatGPT ou d'autres solutions propriétaires. En fait, avec deux GPU A100 40GB (ou un seul GPU 80GB), il est déjà possible d'exécuter LLaMa-3-70B ou Mixtral 8x7B dans de très bonnes conditions. Selon de nombreux benchmarks et avis d'utilisateurs, ces modèles sont de sérieux concurrents à GPT-4.
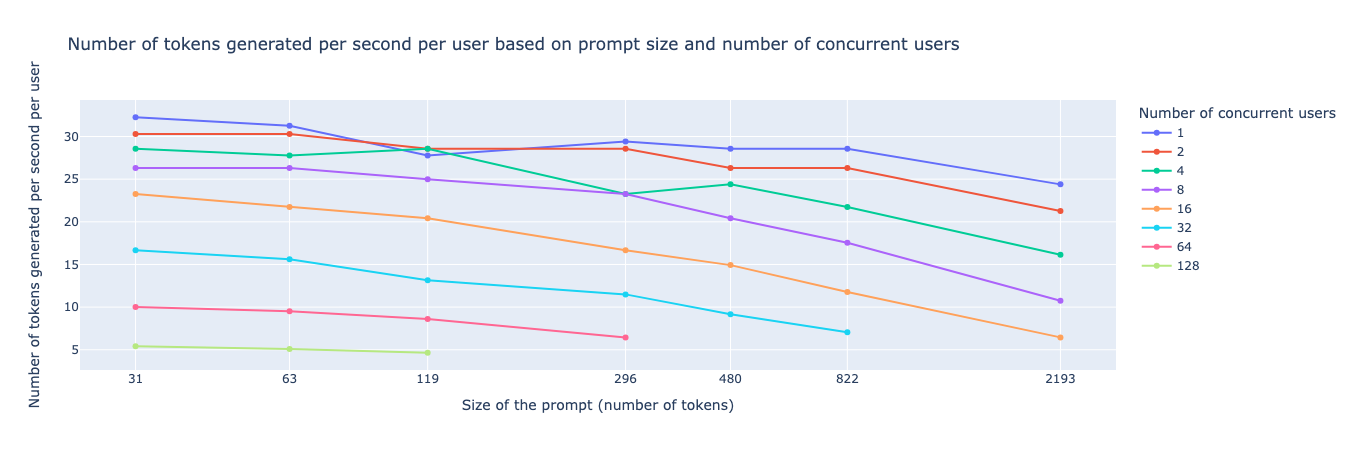 Nombre de jetons générés par seconde et par utilisateur pour Mixtral 8x7B AWQ 4-bits sur 2 A100 40GB
Nombre de jetons générés par seconde et par utilisateur pour Mixtral 8x7B AWQ 4-bits sur 2 A100 40GB
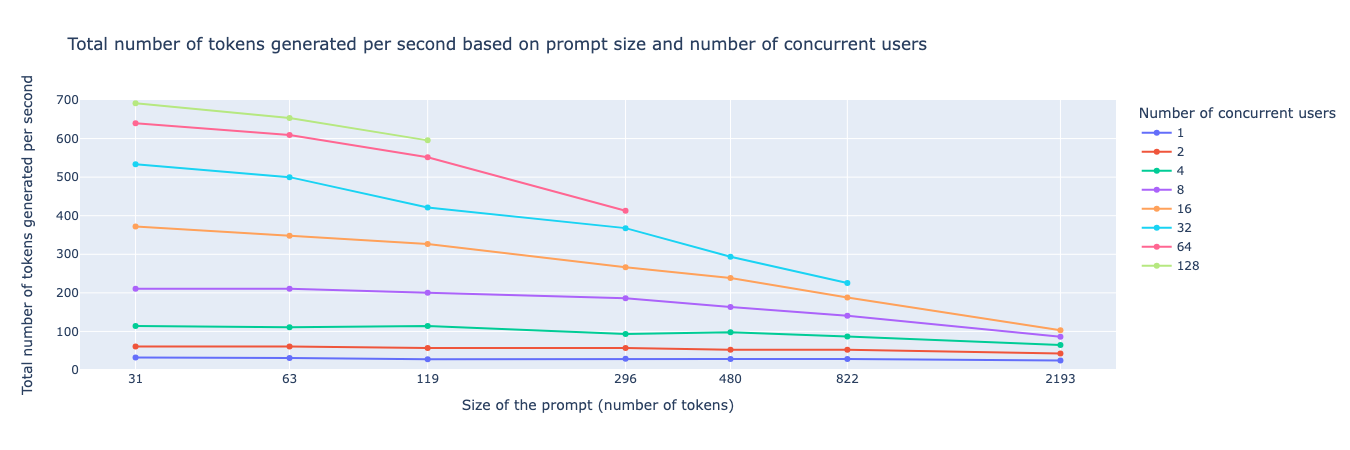 Nombre total de jetons générés par seconde pour Mixtral 8x7B AWQ 4-bits sur 2 A100 40GB
Nombre total de jetons générés par seconde pour Mixtral 8x7B AWQ 4-bits sur 2 A100 40GB
Dans une moindre mesure, il est possible d'héberger des modèles plus petits (de l'ordre de 7 à 30B) et d'obtenir des vitesses de génération extrêmement impressionnantes, surtout si les requêtes sont parallélisées.
Par exemple, nous pouvons observer dans la Figure 1 le nombre de jetons générés par seconde et par utilisateur en fonction du nombre de requêtes simultanées et de la taille de l'invite, et dans la Figure 2 le nombre total de jetons générés par seconde (pour tous les utilisateurs combinés) en fonction du nombre de requêtes simultanées et de la taille des invites. Ainsi, nous pouvons observer que pour un modèle comme Mixtral 8x7B — qui a 49B de paramètres et seulement 12-13B de paramètres actifs à tout moment (architecture MoE) [3] — nous pouvons atteindre jusqu'à 700 jetons/seconde pour 128 requêtes simultanées avec un contexte presque nul (30 jetons), et nous pouvons obtenir une vitesse d'inférence de près de 20 jetons par seconde pour 20 utilisateurs simultanés.
Dans cet article, nous avons présenté une étude comparative des performances de plusieurs modèles de langage de grande taille (LLMs) en fonction des ressources matérielles disponibles. Nos résultats montrent que des modèles tels que Mistral [2][3] et LLaMa [5] peuvent être déployés efficacement sur des GPU V100 et A100, offrant des performances compétitives par rapport à des solutions propriétaires comme ChatGPT [5].
Ces résultats ont des implications significatives pour les communautés académiques et industrielles, fournissant des informations précieuses sur les ressources nécessaires pour déployer des LLMs. Ils soulignent également l'importance de la transparence et de la souveraineté numérique, permettant aux groupes publics et privés de déployer des modèles open-source sans dépendre de solutions propriétaires.
Nous encourageons fortement divers groupes publics et privés à déployer leurs propres solutions LLM, en particulier en utilisant des modèles open-source (ou open-weight). Cette approche non seulement réduit notre dépendance numérique, mais nous rapproche également de la souveraineté de nos données.
Nous remercions le Centre Inria de l'Université de Bordeaux pour leur soutien et leurs ressources, qui ont rendu cette étude possible.