
Avez-vous déjà vu le spectre d’un mandat politique ?
C’est ce que je vous propose de faire avec le Dashboard Overton. Celui-ci vous permet de visualiser le spectre de chacun des mandats de la cinquième république et de découvrir leurs discours et tendances.
Voici l’histoire de son développement. Au menu : scrapping, big data, traitement automatique du langage, intelligence artificielle, dataviz et développement web.
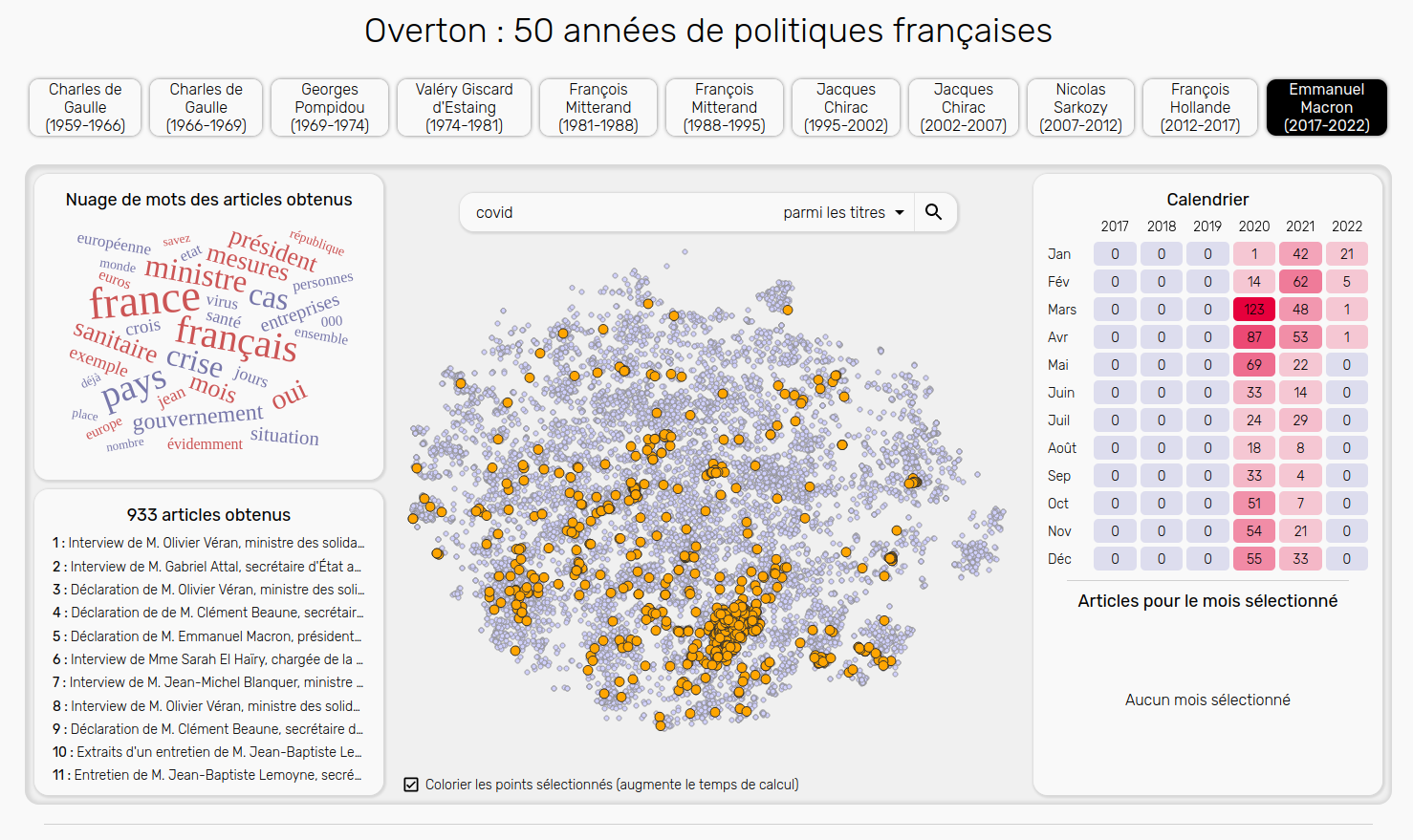 Dashboard Overton
Dashboard Overton
Nous sommes en fin d’année 2021, l’épidémie de coronavirus continue de battre son plein, la fin du premier mandat d’Emmanuel Macron approche grandement, et quelques candidats à l’élection présidentielle prennent déjà d’assaut les plateaux de télévisions pour tenter de propager leurs idées. Choqué par certains des sujets évoqués et convaincu que les idées dites “acceptables” par les médias - et donc l’opinion publique - avaient grandement changé durant ces dernières années, je voulais essayer de montrer, par les données, un éventuel basculement de la politique française.
Je suis donc parti à la recherche d’un dataset et j’ai trouvé vie-publique.fr qui référence plus de 140.000 discours politiques depuis le début de la Vème République. Ces données sont publiques, cependant il n’existe aucun moyen de les télécharger directement. J’ai donc développé un script en python pour télécharger ces 140.000 pages du site web et y extraire près de 100.000 discours annotés, allant de Charles de Gaulle à Emmanuel Macron. Cette étape, bien que simple, a duré près de 5 jours.
Vous pouvez retrouver le code utilisé pour scrapper vie-publique.fr sur ce dépôt github.
 Site web vie-publique.fr
Site web vie-publique.fr
Mais comment visualiser et explorer plus de 100.000 textes, et comment en extraire de l’information ?
C’est ici qu’intervient FlauBERT, un modèle d’intelligence artificielle basé sur les algorithmes BERT de Google, et entraîné par l’INRIA sur plus de 70 Giga Octets de texte français. Pour faire simple, il est capable de transformer une phrase en un vecteur (une suite de nombre) de telle manière que deux phrases proches donneront deux vecteurs proches.
Ainsi, grâce à lui, j’ai converti mes 100.000 discours en autant de vecteur d’environ 700 dimensions (c’est à dire ayant 700 nombres) que j’ai ensuite réduit en deux dimensions grâce à un second algorithme : TSNE.
J’interprète ensuite ces deux dimensions comme deux coordonnées X et Y me permettant de représenter chacun de ces 100.000 textes par un point sur un graphe de telle manière que deux textes ayant des sujets similaires soient proches dans le graphe. Ainsi, nous pouvons distinguer des groupes et des tendances dans nos nuages de points.
J’ai ensuite développé un dashboard permettant de visualiser ces nuages de points, de filtrer les discours et d’accéder aux informations associées (titre, date, mots clés, thématiques, intervenants, texte brute).
Vous pouvez aussi obtenir le nuage de mot et le calendrier associés à une sélection de discours en effectuant une recherche par titre, mots clés, thématique ou intervenant, et naviguer entre les différents mandats présidentiels.
Je vous invite à explorer vous même ces données sur le dashboard en effectuant des recherches de mots-clés tels que “santé”, “guerre”, “économie”, “aviation”, "brexit", “sport”, etc…
Trouvant ceci très satisfaisant, je vous partage en bonus deux timelapses montrant le déroulement de l'algorithme TSNE sur 10.000 données.
Deux timelapses de l'Algorithme T-SNE