
En tant que doctorant en intelligence artificielle et neuroscience, j'ai eu l'opportunité d'encadrer un stagiaire de M1, Virgile Boraud, pour un projet passionnant visant à déployer une solution RAG (Retrieval-Augmented Generation) avec GraphRAG. L'objectif était de créer une documentation interactive basée sur des LLM (Large Language Models) pour une bibliothèque Python dédiée au développement de réseaux de neurones de type Reservoir Computing. Dans cet article, je vais vous raconter notre aventure et les défis que nous avons relevés.
ReservoirPy est une bibliothèque Python essentielle pour le développement de réseaux de neurones de type Reservoir Computing. Cette méthode de calcul est particulièrement efficace pour les tâches séquentielles, les séries chaotiques, et ce sans nécessiter beaucoup de données ni de puissance de calcul. Cependant, les utilisateurs de ReservoirPy, souvent novices en développement informatique, rencontrent des difficultés à configurer les modèles et à comprendre les concepts sous-jacents. Il est crucial de fournir une assistance interactive pour aider ces utilisateurs à surmonter les défis techniques et à tirer pleinement parti de la bibliothèque. C'est pourquoi nous avons décidé de développer une solution basée sur des LLM et des Knowledge Graphs. Les LLM peuvent générer des réponses pertinentes et contextuelles, mais ils souffrent souvent de problèmes d'hallucination. En intégrant des Knowledge Graphs, nous pouvons améliorer la précision et la fiabilité des réponses. L'objectif est de créer une plateforme interactive qui puisse répondre aux questions des utilisateurs de manière précise et contextuelle, tout en leur fournissant des exemples de code et des explications détaillées.
 ReservoirPy sur Github
ReservoirPy sur Github
Pour mener à bien ce projet, une équipe dévouée et compétente était essentielle. Virgile, notre stagiaire de M1, a été le développeur principal du projet. Il a travaillé sur l'intégration des différentes technologies et sur le développement de l'interface utilisateur. Loïc a joué un rôle crucial dans la mise en place de l'infrastructure et dans la configuration des services. Il a également contribué à la création de la configuration nginx. Paul et Xavier ont apporté leur expertise en neuroscience et en intelligence artificielle. Ils ont contribué à la définition des objectifs du projet et à l'évaluation des résultats. La collaboration entre les membres de l'équipe a été essentielle pour surmonter les défis techniques et pour assurer la réussite du projet. En tant qu'encadrant de Virgile, j'ai eu l'opportunité de guider Virgile tout au long du projet, en lui fournissant des conseils et des orientations pour l'aider à atteindre les objectifs fixés.
La mise en place de l'infrastructure a été une étape cruciale pour notre projet. Grâce à l'Inria, à l'équipe SED et à l'équipe derrière Plafrim, nous avons obtenu un accès exclusif à un nœud Sirocco de Plafrim, équipé de deux GPU V100 16Go. Cette machine puissante nous a permis de faire tourner Codestral-22B - un LLM entrainé et distribué par Mistral AI - en un temps record. Initialement, j'ai déployé les services avec screen, mais avec l'aide de Loïc, nous avons opté pour une solution plus robuste en utilisant systemctl. Loïc a également créé une configuration nginx pour exposer notre site web à l'adresse http://chat.reservoirpy.inria.fr/. Cette infrastructure solide nous a permis de surmonter les défis techniques initiaux et de poser les bases pour le développement de notre solution.
Pour améliorer les réponses des LLM, nous avons d'abord exploré la méthode RAG (Retrieval-Augmented Generation). Cette méthode permet de récupérer des sections pertinentes de la documentation avant de générer une réponse, réduisant ainsi les hallucinations. Nous avons développé un simple RAG en Python pour tester cette approche. Les résultats initiaux ont montré une nette amélioration dans la qualité des réponses générées, mais nous avons également appris l'importance de la qualité des données et de la pertinence des embeddings pour obtenir des résultats optimaux. Cette expérience nous a encouragés à aller plus loin en intégrant la méthode GraphRAG.
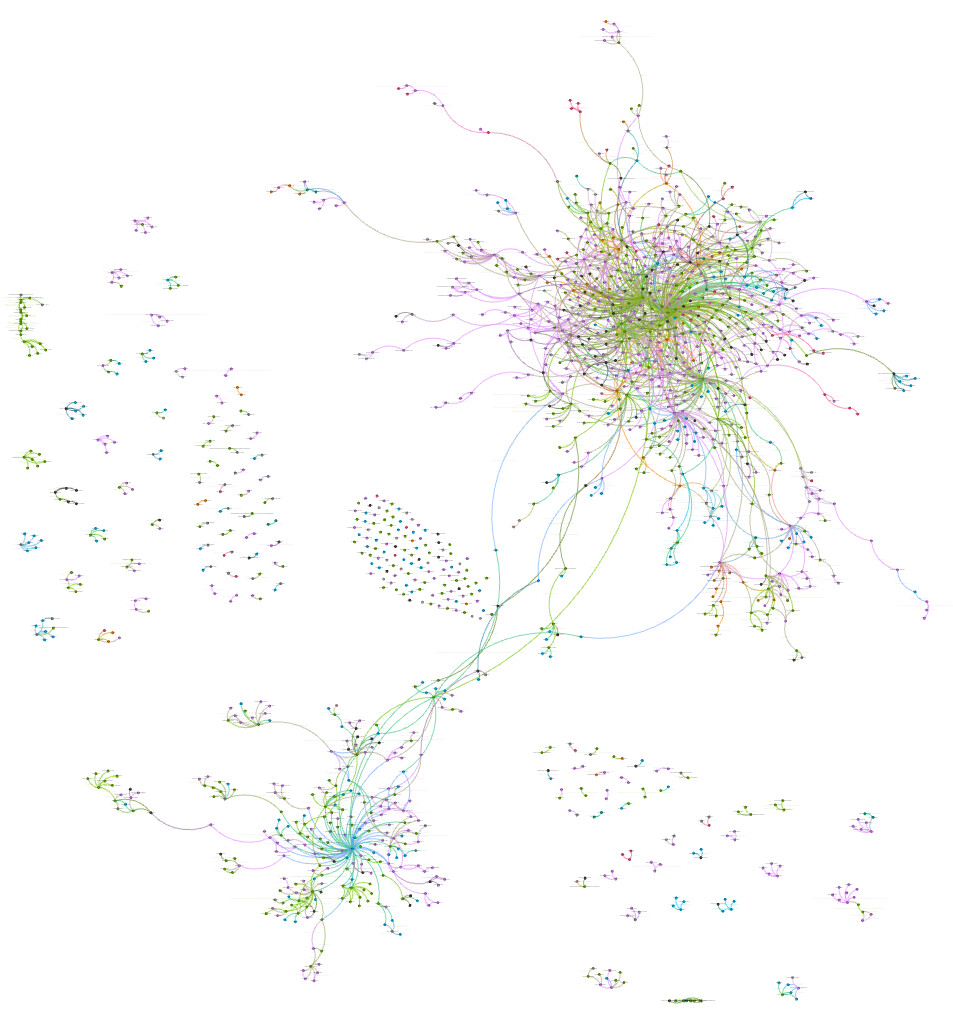 Graph de connaissance obtenu via GraphRAG
Graph de connaissance obtenu via GraphRAG
GraphRAG, développée par Microsoft, utilise des LLM pour extraire des concepts variés (personnes, lieux, objets, actions, etc.) à partir d'un ensemble de textes. Ces concepts sont ensuite associés à des résumés, liés entre eux, et regroupés par famille, créant ainsi un graphe de connaissances. Cette méthode permet d'améliorer la contextualisation et la précision des réponses générées. Virgile a lancé GraphRAG sur l'ensemble des documents collectés pour ReservoirPy, et nous avons obtenu un graphe impressionnant. Les résultats obtenus avec GraphRAG ont été très prometteurs, avec une amélioration significative de la qualité des réponses générées. Cette étape a été essentielle pour atteindre nos objectifs et fournir une assistance interactive de haute qualité aux utilisateurs de ReservoirPy.
Le développement de ReservoirChat a été une étape cruciale de notre projet. L'interface utilisateur, conçue avec la bibliothèque Panel, offre une expérience interactive et intuitive. Les utilisateurs peuvent poser des questions et recevoir des réponses contextuelles et précises, grâce à l'intégration de plusieurs fonctionnalités clés. ReservoirChat utilise des LLM pour générer des réponses, améliorées par des Knowledge Graphs pour une meilleure précision. De plus, la plateforme est capable de fournir des exemples de code et des explications détaillées, rendant l'assistance encore plus complète. Cependant, l'intégration de ces différentes technologies a présenté plusieurs défis techniques, notamment la compatibilité entre les services et la gestion des ressources que nous avons su résoudre avec succès.
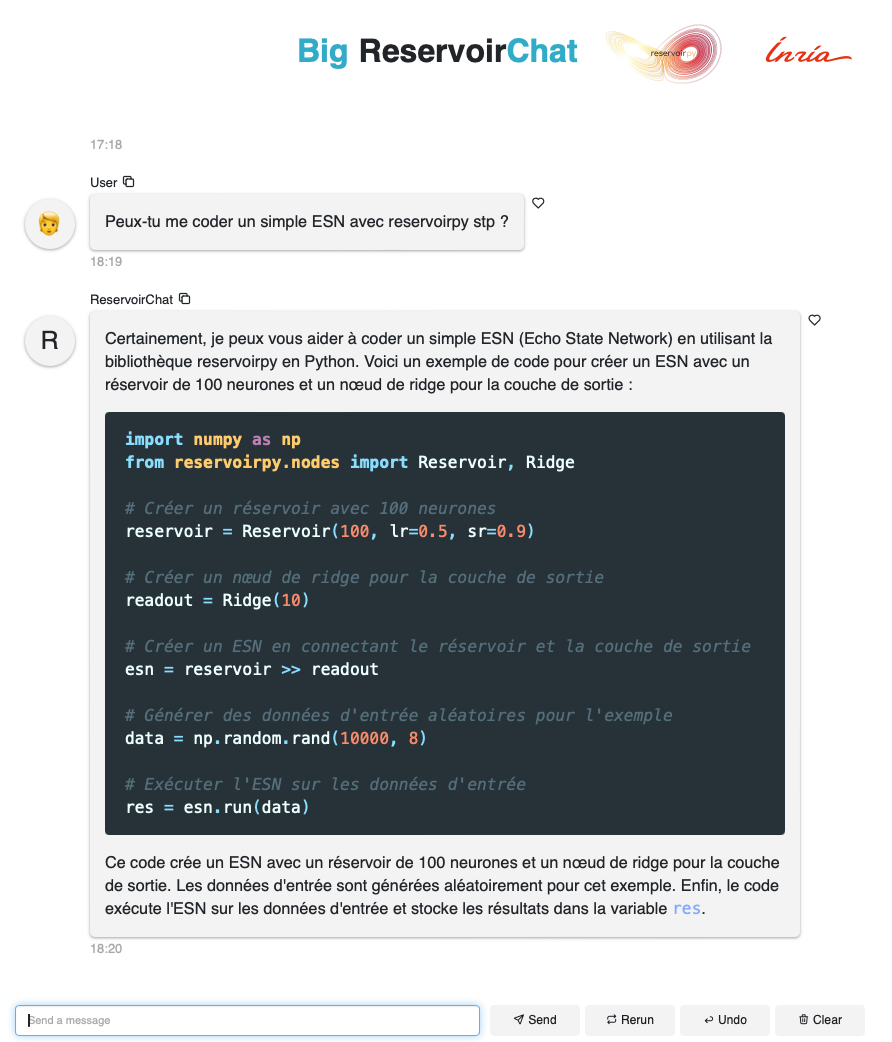 Interface de ReservoirChat
Interface de ReservoirChat
Pour évaluer les performances de ReservoirChat, nous avons adopté une méthodologie de benchmarking. Cette approche consiste à soumettre ReservoirChat à un ensemble de Questions à Choix Multiple (QCM) préparé à l'avance, et à le comparer avec les autres modèles concurrents. Nous avons comparé ses performances avec ChatGPT-4o, Llama3, Codestral, et NotebookLM. Les résultats ont montré que ReservoirChat offre des performances compétitives et fiables, avec une amélioration significative de la qualité des réponses générées grâce à l'intégration des Knowledge Graphs. Cette comparaison a également mis en lumière les forces et les faiblesses de notre solution, nous permettant d'identifier des axes d'amélioration pour l'avenir.
En conclusion, notre projet de développement de ReservoirChat a permis d'atteindre des résultats significatifs et de fournir une assistance interactive aux utilisateurs de ReservoirPy. L'intégration des Knowledge Graphs a considérablement amélioré la précision et la pertinence des réponses générées, montrant l'importance d'utilisation de base de données structurées pour améliorer les performances des LLM.
ReservoirChat offre une nouvelle dimension à l'assistance interactive, permettant aux utilisateurs de mieux comprendre et utiliser la bibliothèque ReservoirPy. Ce projet ouvre la voie à de nouvelles approches et méthodes pour rendre les bibliothèques de développement informatique plus accessibles et interactives.
Je remercie Virgile, Loïc, Paul, Xavier et toute l'équipe pour leur dévouement et leur expertise tout au long du projet. Cette expérience a été enrichissante et stimulante.